Posted 2019-02-20
This notebook originally accompanied a workshop I gave at NYCDH Week, in February of 2019, called “Advanced Topics in Word Embeddings.” (In truth, it’s only somewhat advanced. With a little background in NLP, this could even serve as an introduction to the subject.) You can run the code in a Binder, here.
Word embeddings are among the most discussed subjects in natural language processing, at the moment. If you’re not already familiar with them, there are a lot of great introductions out there. In particular, check out these:
- A classic primer on Word Embeddings, from Google (uses TensorFlow)
- Another word2vec tutorial using TensorFlow
- The original documentation of word2vec
- Spacy Docs on vector similarity
- Gensim Docs
An Example of Document Vectors: Project Gutenberg
This figure shows off some of the things you can do with document vectors. Using just the averaged word vectors of each document, and projecting them onto PCA space, you can see a nice divide between fiction and nonfiction books. In fact, I like to think of the line connecting the upper-left and the lower-right as a vector of “fictionality,” withthe upper-left corner as “highly fictional,” and the lower right as “highly non-fictional.” Curiously, religious texts are right in between.

There’s more on this experiment in this 2015 post.
Getting Started
First, import the libraries below. (Make sure you have the packages beforehand, of course.)
import pandas as pd
import spacy
from glob import glob
# import word2vec
# import gensim
# from gensim.test.utils import common_texts
# from gensim.models import Word2Vec
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
from matplotlib import pyplot as plt
import json
from mpl_toolkits.mplot3d import Axes3D, proj3d #???
from numpy import dot
from numpy.linalg import norm
%matplotlib notebook
plt.rcParams["figure.figsize"] = (12,8)Now load the Spacy data that you downloaded (hopefully) prior to the
workshop. If you don’t have it, or get an error below, you might want to
check out the
documentation that Spacy maintains here for how to download language
models. Download the en_core_web_lg
model.
nlp = spacy.load('en_core_web_lg')Word Vector Similarity
First, let’s make SpaCy “document” objects from a few expressions.
These are fully parsed objects that contain lots of inferred information
about the words present in the document, and their relations. For our
purposes, we’ll be looking at the .vector
property, and comparing documents using the .similarity() method. The .vector is just an average of the word vectors
in the document, where each word vector comes from pre-trained model—the
Stanford GloVe vectors. Just for fun, I’ve taken the examples below from
Monty Python and the Holy Grail, the inspiration for the name
of the Python programming language. (If you haven’t seen
it, this is the scene I’m referencing..)
africanSwallow = nlp('African swallow')
europeanSwallow = nlp('European swallow')
coconut = nlp('coconut')africanSwallow.similarity(europeanSwallow)0.8596378859289445
africanSwallow.similarity(coconut)0.2901231866716321
The .similarity() method is nothing
special. We can implement our own, using dot products and norms:
def similarity(vecA, vecB):
return dot(vecA, vecB) / (norm(vecA, ord=2) * norm(vecB, ord=2))similarity(africanSwallow.vector, europeanSwallow.vector)0.8596379
Analogies (Linear Algebra)
In fact, using our custom similarity function above is probably the easiest way to do word2vec-style vector arithmetic (linear algebra). What will we get if we subtract “European swallow” from “African swallow”?
swallowArithmetic = (africanSwallow.vector - europeanSwallow.vector)To find out, we can make a function that will find all words with
vectors that are most similar to our vector. If there’s a better way of
doing this, let me know! I’m just going through all the possible words
(all the words in nlp.vocab) and comparing
them. This should take a long time.
def mostSimilar(vec):
highestSimilarities = [0]
highestWords = [""]
for w in nlp.vocab:
sim = similarity(vec, w.vector)
if sim > highestSimilarities[-1]:
highestSimilarities.append(sim)
highestWords.append(w.text.lower())
return list(zip(highestWords, highestSimilarities))[-10:]mostSimilar(swallowArithmetic)[('croup', 0.06349668),
('deceased', 0.11223719),
('jambalaya', 0.14376064),
('cobra', 0.17929554),
('addax', 0.18801448),
('tanzania', 0.25093195),
('rhinos', 0.3014531),
('lioness', 0.34080425),
('giraffe', 0.37119308),
('african', 0.5032688)]
Our most similar word here is “african”! So “European swallow” - “African swallow” = “African”! Just out of curiosity, what will it say is the semantic neighborhood of “coconut”?
mostSimilar(coconut.vector)[('jambalaya', 0.24809697),
('tawny', 0.2579049),
('concentrate', 0.35225457),
('lasagna', 0.36302277),
('puddings', 0.4095627),
('peel', 0.47492552),
('eucalyptus', 0.4899935),
('carob', 0.57747585),
('peanut', 0.6609557),
('coconut', 1.0000001)]
Looks like a recipe space. Let’s try the classic word2vec-style analogy, king - man + woman = queen:
king, queen, woman, man = [nlp(w).vector for w in ['king', 'queen', 'woman', 'man']]answer = king - man + womanmostSimilar(answer)[('gorey', 0.03473952),
('deceased', 0.2673984),
('peasant', 0.32680285),
('guardian', 0.3285926),
('comforter', 0.346274),
('virgins', 0.3561441),
('kissing', 0.3649173),
('woman', 0.5150813),
('kingdom', 0.55209804),
('king', 0.802426)]
It doesn’t work quite as well as expected. What about for countries and their capitals? Paris - France + Germany = Berlin?
paris, france, germany = [nlp(w).vector for w in ['Paris', 'France', 'Germany']]
answer = paris - france + germany
mostSimilar(answer)[('orlando', 0.48517892),
('dresden', 0.51174784),
('warsaw', 0.5628617),
('stuttgart', 0.5869507),
('vienna', 0.6086052),
('prague', 0.6289497),
('munich', 0.6677783),
('paris', 0.6961337),
('berlin', 0.75474036),
('germany', 0.8027713)]
It works! If you ignore the word itself (“Germany”), then the next most similar one is “Berlin”!
Pride and Prejudice
Now let’s look at the first bunch of nouns from Pride and Prejudice. It starts:
It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.
However little known the feelings or views of such a man may be on his first entering a neighbourhood, this truth is so well fixed in the minds of the surrounding families, that he is considered the rightful property of some one or other of their daughters.
First, load and process it. We’ll grab just the first fifth of it, so we won’t run out of memory. (And if you still run out of memory, maybe increase that number.)
pride = open('pride.txt').read()pride = pride[:int(len(pride)/5)]prideDoc = nlp(pride)Now grab the first, say, 40 nouns.
prideNouns = [w for w in prideDoc if w.pos_.startswith('N')][:40]
prideNounLabels = [w.lemma_ for w in prideNouns]prideNounLabels[:10]['truth',
'man',
'possession',
'fortune',
'want',
'wife',
'feeling',
'view',
'man',
'neighbourhood',
'truth',
...
Get the vectors of those nouns.
prideNounVecs = [w.vector for w in prideNouns]Verify that they are, in fact, our 300-dimensional vectors.
prideNounVecs[0].shape(300,)
Use PCA to reduce them to three dimensions, just so we can plot them.
reduced = PCA(n_components=3).fit_transform(prideNounVecs)reduced[0].shape(3,)
prideDF = pd.DataFrame(reduced)Plot them interactively, in 3D, just for fun.
%matplotlib notebook
plt.rcParams["figure.figsize"] = (10,8)
def plotResults3D(df, labels):
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(df[0], df[1], df[2], marker='o')
for i, label in enumerate(labels):
ax.text(df.loc[i][0], df.loc[i][1], df.loc[i][2], label)plotResults3D(prideDF, prideNounLabels)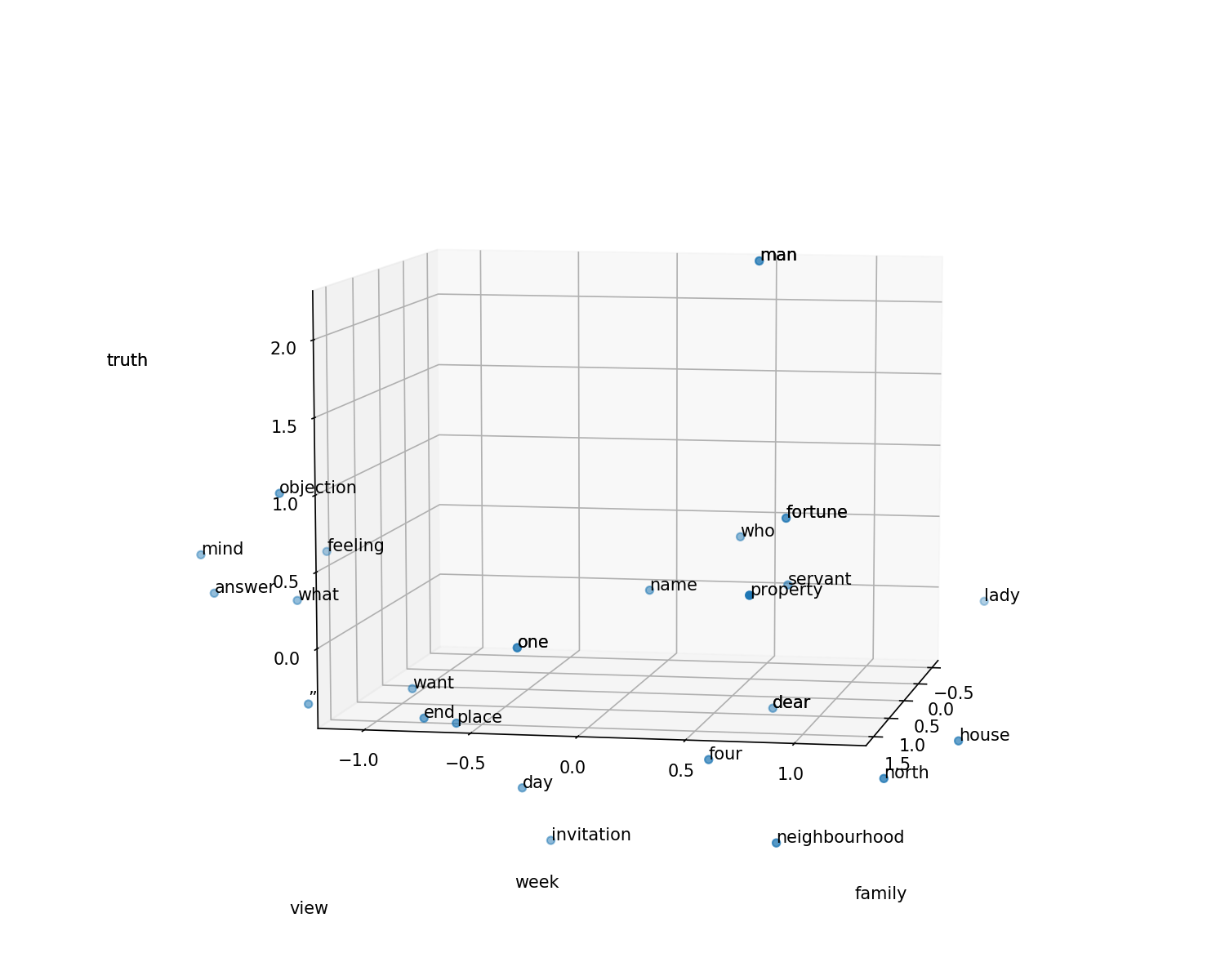
Now we can rewrite the above function so that instead of cycling through all the words ever, it just looks through all the Pride and Prejudice nouns:
# Redo this function with only nouns from Pride and Prejudice
def mostSimilar(vec):
highestSimilarities = [0]
highestWords = [""]
for w in prideNouns:
sim = similarity(vec, w.vector)
if sim > highestSimilarities[-1]:
highestSimilarities.append(sim)
highestWords.append(w.text.lower())
return list(zip(highestWords, highestSimilarities))[-10:]Now we can investigate, more rigorously than just eyeballing the visualization above, the vector neighborhoods of some of these words:
mostSimilar(nlp('fortune').vector)[('', 0), ('truth', 0.3837785), ('man', 0.40059176), ('fortune', 1.0000001)]
Senses
If we treat words as documents, and put them in the same vector space as other documents, we can infer how much like that word the document is, vector-wise. Let’s use four words representing the senses:
senseDocs = [nlp(w) for w in ['sound', 'sight', 'touch', 'smell']]
def whichSense(word):
doc = nlp(word)
return {sense: doc.similarity(sense) for sense in senseDocs}whichSense('symphony'){sound: 0.37716483832358116,
sight: 0.20594014841156277,
touch: 0.19551651130481998,
smell: 0.19852637065751555}
%matplotlib inline
plt.rcParams["figure.figsize"] = (14,8)testWords = 'symphony itchy flower crash'.split()
pd.DataFrame([whichSense(w) for w in testWords], index=testWords).plot(kind='bar')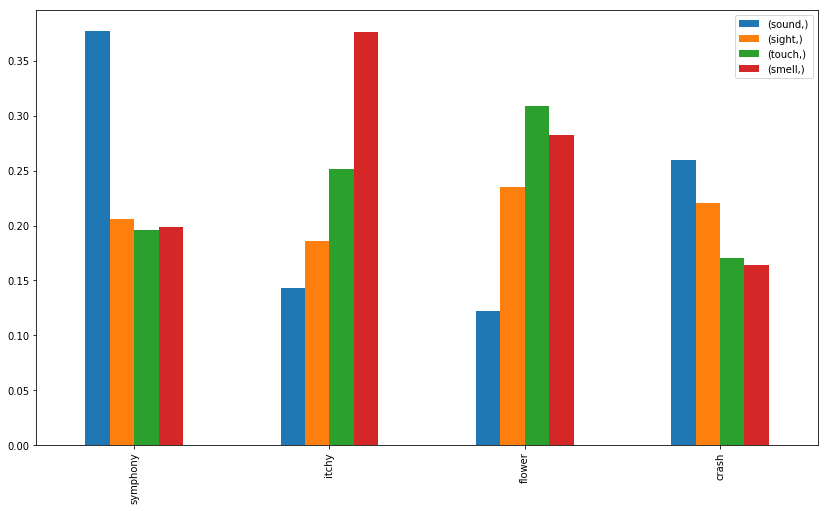
It looks like it correctly guesses that symphony correlates with sound, and also does so with crash, but its guesses for itchy (smell) and for flower (touch) are less intuitive.
The Inaugural Address Corpus
In this repo, I’ve prepared a custom version of the Inaugural Address Corpus included with the NLTK. It just represents the inaugural addresses of most of the US presidents from the 20th and 21st centuries. Let’s compare them using document vectors! First let’s generate parallel lists of documents, labels, and other metadata:
inauguralFilenames = sorted(glob('inaugural/*'))
inauguralLabels = [fn[10:-4] for fn in inauguralFilenames]
inauguralDates = [int(label[:4]) for label in inauguralLabels]
parties = 'rrrbbrrrbbbbbrrbbrrbrrrbbrrbr' # I did this manually. There are probably errors.
inauguralRaw = [open(f, errors="ignore").read() for f in inauguralFilenames]# Sanity check: peek
for i in range(4):
print(inauguralLabels[i][:30], inauguralDates[i], inauguralRaw[i][:30])1901-McKinley 1901 My fellow-citizens, when we as
1905-Roosevelt 1905 My fellow citizens, no people
1909-Taft 1909 My fellow citizens: Anyone who
1913-Wilson 1913 There has been a change of gov
Process them and compute the vectors:
inauguralDocs = [nlp(text) for text in inauguralRaw]inauguralVecs = [doc.vector for doc in inauguralDocs]Now compute a similarity matrix for them. Check the similarity of everything against everything else. There’s probably a more efficient way of doing this, using sparse matrices. If you can improve on this, please send me a pull request!
similarities = []
for vec in inauguralDocs:
thisSimilarities = [vec.similarity(other) for other in inauguralDocs]
similarities.append(thisSimilarities)df = pd.DataFrame(similarities, columns=inauguralLabels, index=inauguralLabels)Now we can use .idmax() to compute the
most semantically similar addresses.
df[df < 1].idxmax()1901-McKinley 1925-Coolidge
1905-Roosevelt 1913-Wilson
1909-Taft 1901-McKinley
1913-Wilson 1905-Roosevelt
1917-Wilson 1905-Roosevelt
1921-Harding 1953-Eisenhower
1925-Coolidge 1933-Roosevelt
1929-Hoover 1901-McKinley
1933-Roosevelt 1925-Coolidge
1937-Roosevelt 1933-Roosevelt
1941-Roosevelt 1937-Roosevelt
1945-Roosevelt 1965-Johnson
1949-Truman 1921-Harding
1953-Eisenhower 1957-Eisenhower
1957-Eisenhower 1953-Eisenhower
1961-Kennedy 2009-Obama
1965-Johnson 1969-Nixon
1969-Nixon 1965-Johnson
1973-Nixon 1981-Reagan
1977-Carter 2009-Obama
1981-Reagan 1985-Reagan
1985-Reagan 1981-Reagan
1989-Bush 1965-Johnson
1993-Clinton 2017-Trump
1997-Clinton 1985-Reagan
2001-Bush 1981-Reagan
2005-Bush 1953-Eisenhower
2009-Obama 1981-Reagan
2017-Trump 1993-Clinton
dtype: object
If we reduce the dimensions here using PCA, we can visualize the similarity in 2D:
embedded = PCA(n_components=2).fit_transform(inauguralVecs)xs, ys = embedded[:,0], embedded[:,1]
for i in range(len(xs)):
plt.scatter(xs[i], ys[i], c=parties[i], s=inauguralDates[i]-1900)
plt.annotate(inauguralLabels[i], (xs[i], ys[i]))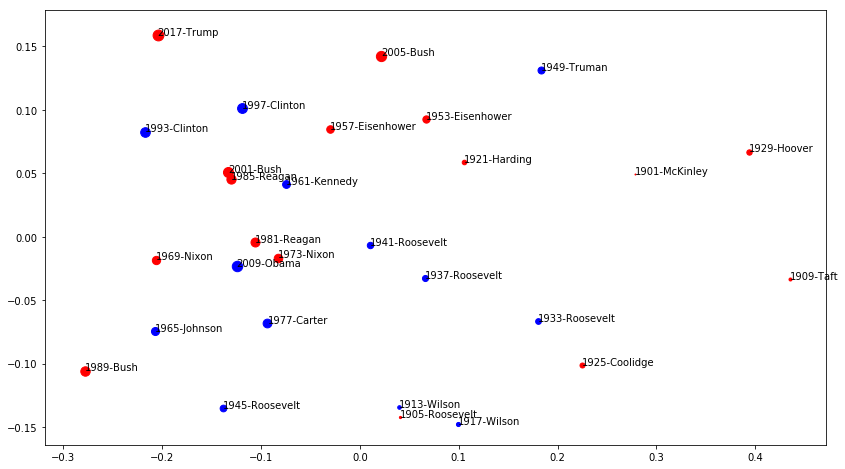
Detective Novels
I’ve prepared a corpus of detective novels, using another notebook in this repository. It contains metadata and full texts of about 10 detective novels. Let’s compute their similarities to certain weapons! It seems the murder took place in the drawing room, with a candlestick, and the murderer was Colonel Mustard!
detectiveJSON = open('detectives.json')
detectivesData = json.load(detectiveJSON)
detectivesData = detectivesData[1:] # Chop off #1, which is actually a duplicatedetectiveTexts = [book['text'] for book in detectivesData]We might want to truncate these texts, so that we’re comparing the same amount of text throughout.
detectiveLengths = [len(text) for text in detectiveTexts]
detectiveLengths[351240, 415961, 440629, 611531, 399572, 242949, 648486, 350142, 288955]
detectiveTextsTruncated = [t[:min(detectiveLengths)] for t in detectiveTexts]detectiveDocs = [nlp(book) for book in detectiveTextsTruncated] # This should take a whileextraWords = "gun knife snake diamond".split()
extraDocs = [nlp(word) for word in extraWords]
extraVecs = [doc.vector for doc in extraDocs]detectiveVecs = [doc.vector for doc in detectiveDocs]
detectiveLabels = [doc['author'].split(',')[0] + '-' + doc['title'][:20] for doc in detectivesData]detectiveLabels['Collins-The Haunted Hotel: A',
'Rohmer-The Insidious Dr. Fu',
'Chesterton-The Innocence of Fat',
'Doyle-The Return of Sherlo',
'Chesterton-The Wisdom of Father',
'Doyle-A Study in Scarlet',
"Gaboriau-The Count's Millions",
"Rinehart-Where There's a Will",
"Michelson-In the Bishop's Carr"]
pcaOut = PCA(n_components=10).fit_transform(detectiveVecs + extraVecs)
tsneOut = TSNE(n_components=2).fit_transform(pcaOut)xs, ys = tsneOut[:,0], tsneOut[:,1]
for i in range(len(xs)):
plt.scatter(xs[i], ys[i])
plt.annotate((detectiveLabels + extraWords)[i], (xs[i], ys[i]))
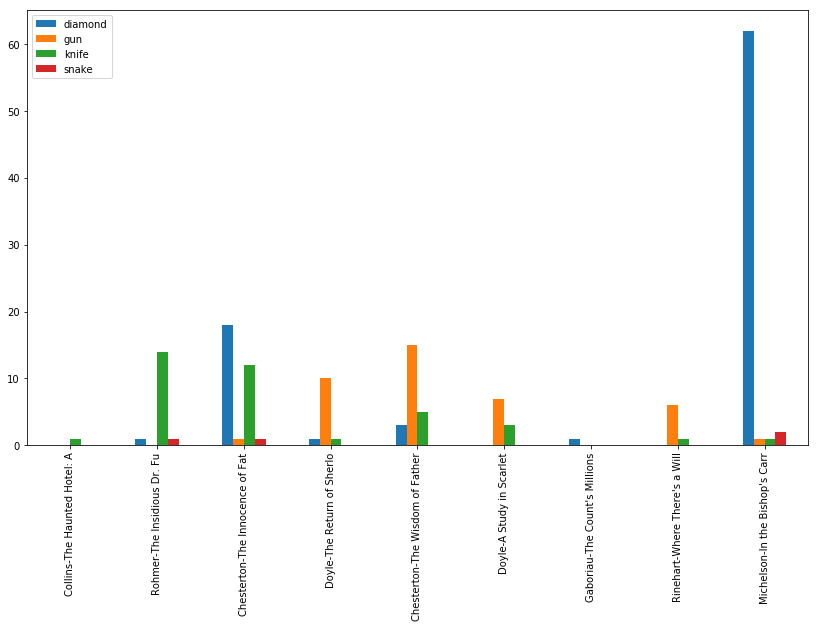
If you read the summaries of some of these novels on Wikipedia, this isn’t terrible. To check, let’s just see how often these words occur in the novels.
# Sanity check
counts = {label: {w: 0 for w in extraWords} for label in detectiveLabels}
for i, doc in enumerate(detectiveDocs):
for w in doc:
if w.lemma_ in extraWords:
counts[detectiveLabels[i]][w.lemma_] += 1pd.DataFrame(counts).T.plot(kind='bar')