Posted 2016-10-08
In the influential 1948 paper “A Mathematical Theory of Communication,” the mathematician Claude Shannon conducts a thought experiment to construct an algorithmic approximation of language. The algorithm can be described like this:
Choose a book at random from your bookshelf, and open to a random page. Choose a random word on that page. Record this word.
Open another book at random, and read until you find the word you just recorded. Record the word that follows this word. Repeat this step as many times as you like.
This process, when applied to the speech of a particular character or author, can mathematically approximate that character’s speech. While that may be a difficult task to accomplish manually, it’s a trivial computational task using semantically encoded texts. For texts that are encoded in TEI XML, such as the Platonic dialogues available through the Perseus Digital Library, a character’s speech is encoded like this:
<sp><speaker>Socrates</speaker><p>Dear Phaedrus, whither away, and where do you come from?</p></sp>
This markup makes it trivial to exact all of a character’s speech
using an XPATH expression like .//sp[speaker’Socrates’]/p=. Once that speech is
extracted, this same probabilistic process can then be abstracted and
applied to the metasyntactic or textual level, so that it can generate
not only strings of words, but textual structures like dialogues. I
recently wrote a
program that implements this idea. Here’s a dialogue that the
program generated, in which it tries to emulate the Platonic dialogue
Phaedrus, and also emulate the speech of each character in the
dialogue:
Socrates: Do you came down, attain immortality as we must first make the longest ears—No, Phaedrus, then pray to agree and writing speeches.
Phaedrus: Certainly. Yes, certainly. What he must speak then I think he speaks is being guided about, which you mean?
Socrates: Do you seem less sense about rhetoric.
Phaedrus: True. What?
This is nonsense, of course, but you can still hear the voices of the characters come through. Socrates sounds vaguely like Socrates, and Phaedrus sounds vaguely like Phaedrus.
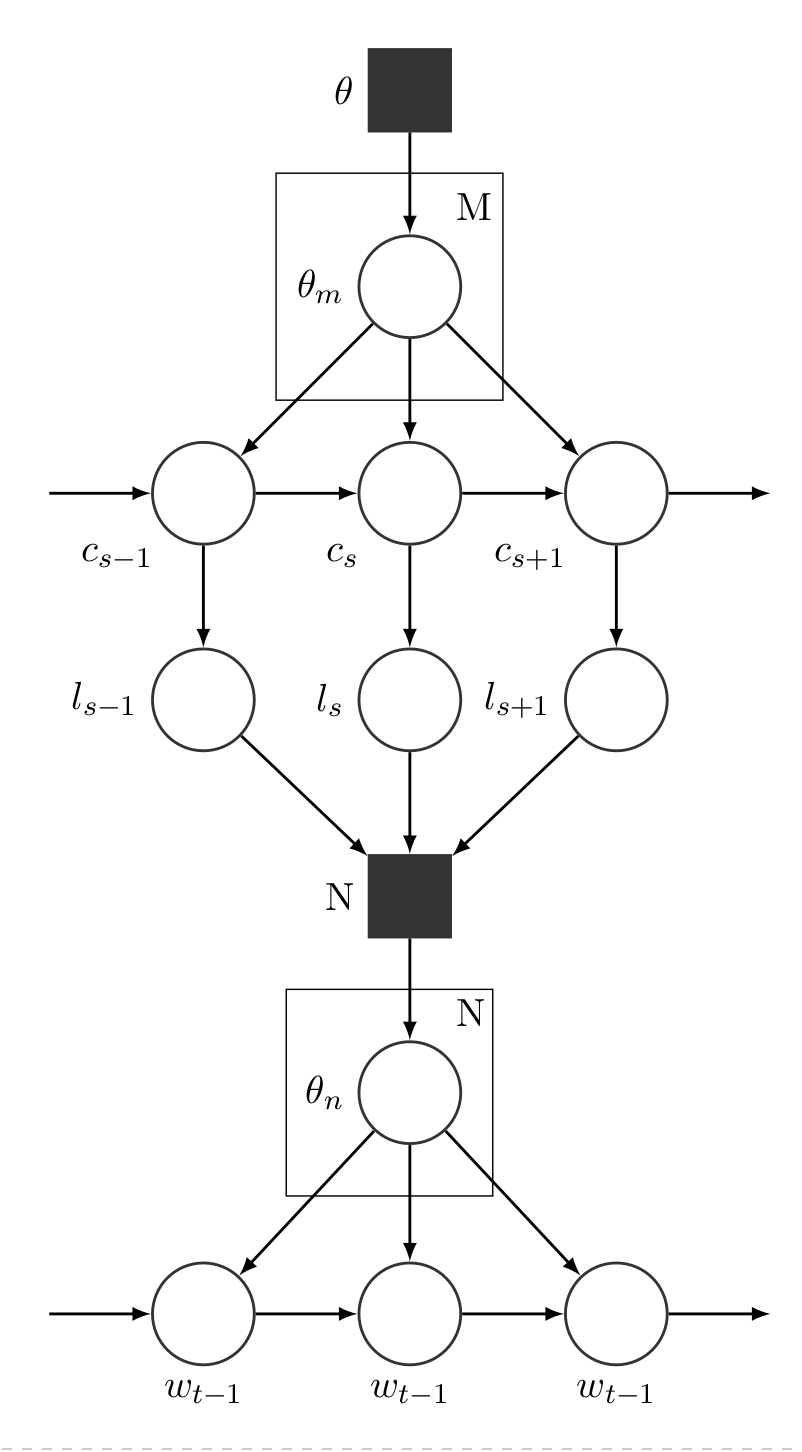
Here’s how it works. Figure 1 shows a graphical model that represents
the probabilistic process of the algorithm. The user-supplied value of
M denotes the number of lines to be
generated (in the above example this is 4). This determines the number
of character utterances that will be generated. Each of those
utterances, c, are determined by the
previous utterancẹ̣—Socrates will speak after Phaedrus, and vice versa.
For each character choice, the length of each utterance, l, is probabilistically determined by the text.
Each of those lengths is then fed into a Markov chain generator which is
given a probability table of that character’s speech. Using that table,
words are generated, where the probability of each is determined by the
preceding word.
The Socratic dialogue generator should work with any Platonic dialogue in the Perseus library. Just specify the filename, the two characters you want to have talk to each other, and how many lines of dialogue you want to generate.