Posted 2016-02-03
Or, Computational Poetic Generation as Literary Analysis
Note: this project may also be found here, in its original format as an iPython notebook.
“In so far as it represented man’s harnessing of energy through craft, the machine became the most characteristic emblem of the Vorticist movement, more significant … than the vortex itself.” (Bush 36)
Ezra Pound’s Cantos, whether understood as vorticist, imagist, ideogrammatic, or otherwise, is a poem that is the product of those schools, modes, and procedures. Since the techniques of the Cantos, like those of a cubist painting, are often foregrounded, critical works have been able to postulate about their composition in great detail, in some cases pinpointing the exact source materials for Pound’s collages and translations. With the exception of a few other highly allusory works—“The Wasteland,” for instance—few other modern poems are as richly and thoroughly annotated. One might even venture that there is almost enough metatextual data in the many handbooks to the Cantos—William Cookson’s, Roland’s John’s, George Kerns’s, or Carroll Terrell’s, just to name a few—to reconstruct the poem itself. Given the source materials, composition techniques, themes, meter, and style, it might just be possible to design an algorithm to combine these elements in just the right way to generate a canto. Although the generated canto is unlikely to be a work of great artistic merit, the process of translating the procedure of poetic composition into an algorithm will help us to understand its minute machinations. The following describes an experiment to attempt just that—the translation of literary criticism into a generative algorithm, which hopes to be revealing about the structure of the Cantos, the shape of its critical response, and the limitations of algorithmic composition.
Among the many analogies critics have made between the Cantos and the visual arts, Jacob Korg compares the poem’s techniques to those of collage. “The literary equivalent of the painter’s collage is,” he explains, “quotation—not conventional quotation, but the kind that presents itself as an interpolation, interrupting the text, and even conflicting with the writer’s purposes, as if it were an eruption of raw reality” (96). Since algorithmically generated language is still in its infancy, mostly belonging to the domain of semantically agnostic probabilistic models, the collage technique of the Cantos, and in particular Pound’s use of direct quotation, is what makes the epic one of the most appropriate poems to attempt to programmatically emulate. As John Childs puts it, “hardly a page of the Draft of XXX Cantos goes by without the insertion into the poem of a word or phrase drawn from an author other than Pound” (18). By identifying these source materials, and designing functions to extract from them and mix them in appropriate ways, we might be able to create poems similar to Pound’s.
The Experiment
The following is a experiment along the borders of computational and
critical methodologies. The format of this investigation, an IPython notebook containing
text and code, represents an attempt to problematize the distinction
between computer science and literary criticism by intentionally
combining the language of both. Some might argue that this paper is
already at least half obscure for its intended audience, since most
literary scholars are unfamiliar with programming languages, and most
coders are unfamiliar with the language of literary study. To help
dissolve this linguistic barrier, I have used the Python programming
language, whose idioms are closest to English, and I have explained some
of the logic behind the program’s functions using interpolated or inline
comments (text following the # symbol)
wherever possible. However, a few key concepts of Python are necessary
to explain here briefly, in order to explain the fundamental
programmatic structures below. This table shows a few types of Python
expressions, along with their explanations in English:
| Python Expression | Meaning |
|---|---|
myVariable = "a " + "test" |
This concatenates the text “a” and “test” and stores the result in a
variable called myVariable. Now myVariable contains the text “a test.” |
def myFunction(x): ... return y |
This defines the function myFunction,
accepts the input X, and returns the output Y. |
myList[0] |
The brackets here indicate an index of the list. This expression returns the 0th, i.e. first, element of the list myList. |
[x/2 for x in myList] |
This list comprehension defines a new list generated from an
operation performed on every element of another list. This list
represents half of every element X in the list myList. |
With these foundations and the interlinear explanations, it should be
possible to read the algorithms below. Additionally, text following a
pound sign (#) and text enclosed in triple
quotes (""") is typically explanatory
commentary.
"""
In this section, we will declare the software libraries that we will
need for the code to follow.
"""
# Most of the text analysis done below is done with the help of the
# Natural Language Toolkit, or NLTK, a Python library for text analysis.
# See http://www.nltk.org for more information.
import nltk
# WordNet is a module in the NLTK that allows for easy navigation of the
# Princeton WordNet, a hierarchical lexical database.
from nltk.corpus import wordnet as wn
# Stopwords are commonly-used words like "a," "the," or "and," and
# this list of stopwords is useful for filtering them out of wordlists.
from nltk.corpus import stopwords
# These two machine translation libraries use the Google Translate API.
import goslate
from textblob import TextBlob
# Regular expressions allow us to search for and select text in a
# sophisticated way.
import re
# This library allows us to smartly count things.
from collections import Counter
# Random number generation allows us to randomly choose things.
import random
# This allows us to work with files located within directories
# in the filesystem.
from os import listdir
# This allows us to identify punctuation.
import string
# Pandas is a sophisticated data science library, that allows for
# data transformation and visualization.
import pandas as pd
# This turns on the option to show data visualizations in this notebook,
# and not in separate window.
%matplotlib inline
# This is a library for data visualization.
import matplotlib.pyplot as plt
# This sets the "ggplot" style for visualizations.
plt.style.use('ggplot')
# This library allows for text wrapping (e.g. line breaks).
import textwrapIn order to generate cantos, we’ll first need to study their form.
We’ll need to determine the length of a canto, its numbers of stanzas,
and its indentation fingerprint. I’ve prepared a markdown-formatted text
file, cantosI-X.md below, which contains
the text of Canto I through Canto X from A Draft of XXX Cantos,
so that the text might be programmatically analyzed. This first class,
CantosFile, reads this text, breaks it up
by header, and stores it in memory.
class CantosFile():
"""
Deals with the file containing transcriptions of the original
Cantos.
"""
# Open the text file and read its contents.
cantos = open('text/cantosI-X.md').read()
# Split the file by header marker ("#"), and take off the first part,
# which is the title, and is not useful for our analysis.
cantosList = cantos.split('#')[1:]
# Count the number of cantos in this file by counting these text
# segments.
numCantos = len(cantosList)Now that the file has been read into memory, we will study each canto
individually with the CantoReader class
below, which will read an individual canto and return information about
it, such as the number of lines, number of stanzas, proportions of each,
and information about the canto’s indentation.
class CantoReader(CantosFile):
"""
A class to read individual cantos and return statistics about them
that will be used by the CantoWriter class. This class accepts the
canto number as an argument, so that CantoReader(1) returns a
CantoReader object for Canto I.
"""
def __init__(self, cantoNumber):
"""
When this class is instanted, it will automatically store a copy
of the canto number (e.g. 4 for Canto IV), and make a copy of that
canto's text for analysis.
"""
# Store a copy of the canto number.
self.cantoNumber = cantoNumber
# Adjust this number, since Python starts counting at zero,
# but cantos are numbered starting with 1.
cantoNumber = cantoNumber-1
# Get the full text of the canto.
self.allText = self.cantosList[cantoNumber]
@property
def lines(self):
"""
Break up the canto into lines, and clean up any unnecessary
lines.
"""
# First, split the canto into lines.
lines = self.allText.split('\n')
# Next, remove the header.
noheader = lines[2:]
# So long as there is blank whitespace at the end of the
# canto, keep removing it, so that we're not counting extranneous
# lines.
while noheader[-1].isspace() or len(noheader[-1]) == 0:
noheader.pop()
return noheader # Return the cleaned version.
@property
def text(self):
"""
Get the text of the canto, cleaned by the `lines` function above,
but join it together, so that it's not broken into lines.
"""
return "\n".join(self.lines)
@property
def stanzas(self):
"""
Break the canto into stanzas by finding double line breaks
(`\n\n`) and dividing the text along those lines.
"""
return nltk.tokenize.regexp_tokenize(self.text, '\n\n', gaps=True)
@property
def numLines(self):
""" Count the number of lines in the canto. """
return len(self.lines)
@property
def numStanzas(self):
"""Count the number of stanzas in a canto."""
return len(self.stanzas)
@property
def stanzaLengths(self):
"""Determine the length of each stanza in the canto, in lines."""
return [len(stanza.split('\n')) for stanza in self.stanzas]
@property
def stanzaPercentages(self):
"""
Determine the proportion of the total canto's lines
represented by its stanzas. This returns a list like
`[0.7402597402597403, 0.24675324675324675]` (for Canto I)
that means that the first stanza takes up about 74% of the total
canto, and the second stanza takes up about 25%.
"""
return [stanzaLength / self.numLines for stanzaLength in self.stanzaLengths]
@property
def indentation(self):
"""
Get a list of indentation levels for each line in the canto.
This returns a list like `[0, 0, 8]` if the first line is flush
left, the second line is flush left, and the third line is
indented by eight spaces.
"""
results = [] # Initialize an empty list to contain our results.
for line in self.lines: # Iterate through each line,
match = re.search('\S', line) # looking for whitespace,
if match is not None: # and if whitespace is found,
# append the location of the first non-whitespace character
# to the list.
results.append(match.start())
else:
# otherwise, the line is flush left, so its indentation
# level is zero. Append zero.
results.append(0)
return results
@property
def indentationStats(self):
"""
Returns a dictionary of indentation levels with their corresponding counts and percentages.
For Canto I, this is {8: [3, 0.0384...]}, since there are three lines indented 8 spaces,
which make up around 3-4% of the total poem.
"""
stats = Counter(self.indentation) # Count the indented lines.
statsDict = {} # Initialize a new "dictionary," or associative array.
# Iterate through each indentation level in the indentation statistics,
for indentLevel in stats:
if indentLevel > 0: # ignoring lines that are flush-left, and
# divide by the total lines of the poem.
statsDict[indentLevel] = [stats[indentLevel], stats[indentLevel] / self.numLines]
return statsDict
def getInfo(self):
"""
Gets all information about this canto, and prints it, so that it is
easily human-readable.
"""
print('Canto number: ', self.cantoNumber)
print('Number of lines: ', self.numLines)
print('Number of stanzas: ', self.numStanzas)
print('Length of stanzas: ', self.stanzaLengths)
print('Stanza Percentages', self.stanzaPercentages)
print('Indentation statistics: ', self.indentationStats)Now we’ll need a set of functions for reading multiple cantos at a time, so that we don’t have to read them each individually. The following class automates the bulk analysis of cantos, so that information about all of the cantos is easily available.
class CantosReader(CantosFile):
def __init__(self):
"""
When this class is instantiated, use the `cantoReader` class to
gather information about each canto. Store this in a list of
canto "objects," which will be a meta-list of canto statistics.
"""
self.cantoObjects = [CantoReader(i) for i in range(1, self.numCantos+1)]
def getAllInfo(self):
""" Print statistics for all cantos in the file. """
# Iterate through the list of all cantos.
for cantoObject in self.cantoObjects:
# Print the statistics for the current canto.
cantoObject.getInfo()
# Add a little spacing to make it look nice.
print('\n')
@property
def lineLengths(self):
""" Make a list of all line lengths for all cantos. """
return [canto.numLines for canto in self.cantoObjects]
def getNumStanzas(self):
""" Make a list of all stanza counts for all cantos. """
return [canto.numStanzas for canto in self.cantoObjects]
@property
def stanzaLengths(self):
""" Get all the lengths of all the stanzas, grouped by canto. """
stanzaList = []
for cantoObject in self.cantoObjects:
stanzaList.append(cantoObject.stanzaLengths)
return stanzaListNow let’s use these functions to find information about cantos I-X.
CantosReader().getAllInfo()Canto number: 1
Number of lines: 77
Number of stanzas: 2
Length of stanzas: [57, 19]
Stanza Percentages [0.7402597402597403, 0.24675324675324675]
Indentation statistics: {8: [3, 0.03896103896103896]}
Canto number: 2
Number of lines: 162
Number of stanzas: 6
Length of stanzas: [39, 62, 28, 17, 6, 5]
Stanza Percentages [0.24074074074074073, 0.38271604938271603, 0.1728395061728395, 0.10493827160493827, 0.037037037037037035, 0.030864197530864196]
Indentation statistics: {8: [53, 0.3271604938271605], 9: [7, 0.043209876543209874], 10: [2, 0.012345679012345678]}
Canto number: 3
Number of lines: 43
Number of stanzas: 2
Length of stanzas: [19, 23]
Stanza Percentages [0.4418604651162791, 0.5348837209302325]
Indentation statistics: {8: [2, 0.046511627906976744]}
Canto number: 4
Number of lines: 136
Number of stanzas: 8
Length of stanzas: [12, 44, 12, 13, 7, 12, 11, 18]
Stanza Percentages [0.08823529411764706, 0.3235294117647059, 0.08823529411764706, 0.09558823529411764, 0.051470588235294115, 0.08823529411764706, 0.08088235294117647, 0.1323529411764706]
Indentation statistics: {8: [42, 0.3088235294117647], 10: [1, 0.007352941176470588]}
Canto number: 5
Number of lines: 130
Number of stanzas: 3
Length of stanzas: [59, 7, 62]
Stanza Percentages [0.45384615384615384, 0.05384615384615385, 0.47692307692307695]
Indentation statistics: {8: [19, 0.14615384615384616], 19: [1, 0.007692307692307693], 46: [1, 0.007692307692307693]}
Canto number: 6
Number of lines: 81
Number of stanzas: 4
Length of stanzas: [36, 17, 21, 4]
Stanza Percentages [0.4444444444444444, 0.20987654320987653, 0.25925925925925924, 0.04938271604938271]
Indentation statistics: {8: [20, 0.24691358024691357], 30: [2, 0.024691358024691357]}
Canto number: 7
Number of lines: 137
Number of stanzas: 9
Length of stanzas: [15, 1, 2, 40, 22, 8, 12, 7, 22]
Stanza Percentages [0.10948905109489052, 0.0072992700729927005, 0.014598540145985401, 0.291970802919708, 0.16058394160583941, 0.058394160583941604, 0.08759124087591241, 0.051094890510948905, 0.16058394160583941]
Indentation statistics: {8: [31, 0.22627737226277372]}
Canto number: 8
Number of lines: 183
Number of stanzas: 5
Length of stanzas: [56, 21, 23, 57, 22]
Stanza Percentages [0.30601092896174864, 0.11475409836065574, 0.12568306010928962, 0.3114754098360656, 0.12021857923497267]
Indentation statistics: {16: [1, 0.00546448087431694], 17: [1, 0.00546448087431694], 18: [2, 0.01092896174863388], 22: [1, 0.00546448087431694], 23: [5, 0.0273224043715847], 8: [17, 0.09289617486338798], 41: [1, 0.00546448087431694], 11: [1, 0.00546448087431694], 13: [4, 0.02185792349726776], 30: [3, 0.01639344262295082], 24: [2, 0.01092896174863388]}
Canto number: 9
Number of lines: 268
Number of stanzas: 15
Length of stanzas: [45, 31, 17, 4, 42, 1, 1, 21, 14, 2, 2, 2, 2, 57, 13]
Stanza Percentages [0.16791044776119404, 0.11567164179104478, 0.06343283582089553, 0.014925373134328358, 0.15671641791044777, 0.0037313432835820895, 0.0037313432835820895, 0.07835820895522388, 0.05223880597014925, 0.007462686567164179, 0.007462686567164179, 0.007462686567164179, 0.007462686567164179, 0.2126865671641791, 0.048507462686567165]
Indentation statistics: {8: [62, 0.23134328358208955], 34: [2, 0.007462686567164179], 20: [1, 0.0037313432835820895], 22: [1, 0.0037313432835820895], 24: [1, 0.0037313432835820895], 43: [1, 0.0037313432835820895], 28: [1, 0.0037313432835820895], 46: [1, 0.0037313432835820895], 15: [2, 0.007462686567164179]}
Canto number: 10
Number of lines: 194
Number of stanzas: 14
Length of stanzas: [60, 27, 11, 10, 5, 3, 2, 11, 8, 4, 2, 12, 18, 8]
Stanza Percentages [0.30927835051546393, 0.13917525773195877, 0.05670103092783505, 0.05154639175257732, 0.02577319587628866, 0.015463917525773196, 0.010309278350515464, 0.05670103092783505, 0.041237113402061855, 0.020618556701030927, 0.010309278350515464, 0.061855670103092786, 0.09278350515463918, 0.041237113402061855]
Indentation statistics: {8: [34, 0.17525773195876287], 1: [1, 0.005154639175257732], 19: [1, 0.005154639175257732], 31: [2, 0.010309278350515464], 39: [1, 0.005154639175257732]}
Since that format is not very easy to read, it might be more helpful to visualize some of this information. First, let’s examine stanza lengths, to get an idea of how long our generated stanzas need to be, and how variable stanza lengths will be. The chart below represents Canto I - Canto V.
df = pd.DataFrame(CantosReader().stanzaLengths)[:4]
df.plot(kind='bar', figsize=(16,8), alpha=0.5)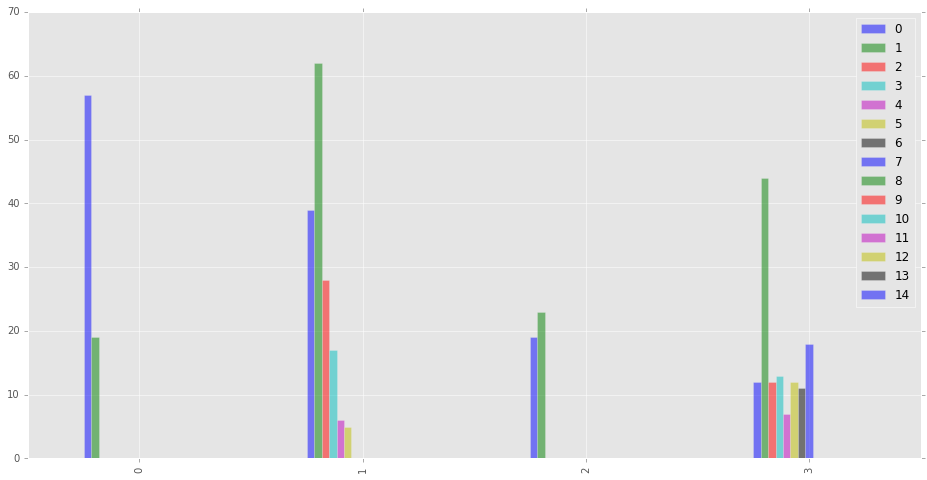
Judging from the number of stanza divisions and the variation in the lengths of the stanzas, Cantos I-IV appear to alternate between simple and complex line grouping systems. With this information, it might be best to design individual canto writer classes for each canto, rather than try to design a canto-agnostic generator.
Now let’s examine the total line lengths of the first ten cantos.
df = pd.DataFrame(CantosReader().lineLengths)
df.plot(kind='bar', figsize=(16,8), alpha=0.5)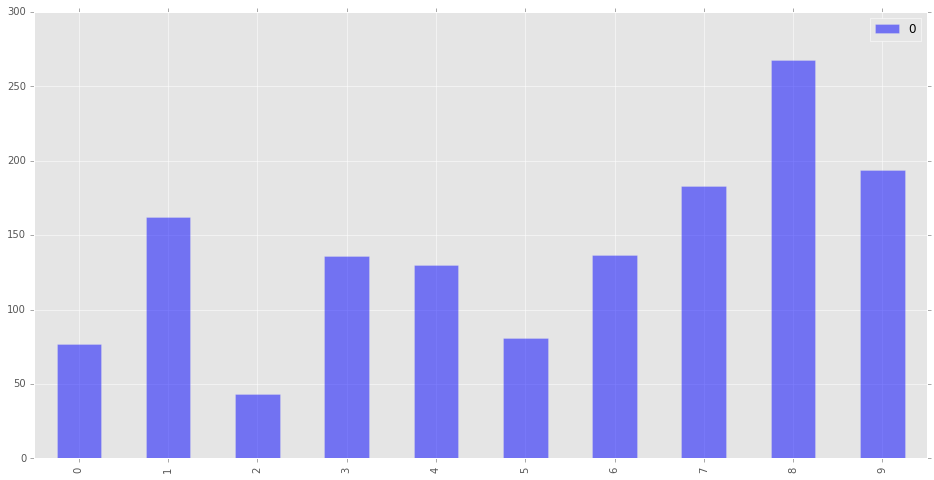
Here again, the variation is immense, further solidifying the idea
that individual subclasses need to be written for each canto. However,
since it’d be best not to repeat code for a particular canto, it will be
useful to write a parent class that will serve as a toolbox. The
following class contains “helper” functions which will be used by the
canto subclasses CantoI, CantoII, and so on.
class CantoWriter:
"""
This class contains "helper" functions which will be used by the CantoI,
CantoII, etc, subclasses. Underscores in the function names indicate
when a function is designed for use by another function, and not meant
to be executed directly.
"""
def _untokenize(self, line):
# Wordnet likes to use underscores for compound words,
# so we have to replace those.
line = [token.replace('_', ' ') for token in line]
# Join broken (tokenized) words like ["do", "n't"].
tokens = [" "+i if not i.startswith("'") and i not in string.punctuation else i for i in line]
# Join everything else, and remove extranneous whitespace.
return "".join(tokens).strip()
def _translatePOS(self, pos):
# POS tagging returns a certain shorthand for parts of speech.
# Let's translate this into something WordNet can understand.
if pos[0]=='N':
return wn.NOUN
if pos[0]=='V':
return wn.VERB
if pos[0]=='J':
return wn.ADJ
if pos[0]=='R':
return wn.ADV
else:
return None
def _getSynonyms(self, posword, includeHyponyms=False):
# accepts tuples of (word, POS)
"""
This function gets synonyms from the Princeton WordNet, optionally
adding hyponyms, if desired. The function accepts input in the form
(word, part-of-speech).
"""
# Get the word.
word = posword[0]
# Get the part-of-speech and translate it to something WordNet
# can understand.
pos = self._translatePOS(posword[1])
# Make a list of stopwords,
stop = stopwords.words('english')
if word not in stop: # and ignore them.
synsets = wn.synsets(word) # Look up the words in WordNet.
else:
synsets = [] # Otherwise, return a blank list.
if len(synsets) > 0:
# Find the word's hyponyms, flattening the list if necessary.
hyponyms = sum([x.lemma_names() for x in synsets[0].hyponyms()], [])
# Find synonyms.
synonyms = synsets[0].lemma_names()
synonyms = [word] + synonyms
if includeHyponyms:
return synonyms + hyponyms
else:
return synonyms
else:
return [word]
def formatLines(self, lines, originalCantoNum):
"""
Using the original canto as a model, this will break up a given
set of lines into stanzas, and indent some of the lines.
It gets the stanza and indentation percentages from CantoReader,
and applies those percentages to the newly-generated text.
"""
# Read the original canto to get statistics.
originalCanto = CantoReader(originalCantoNum)
# We need to know how long the generated poem is so far.
numGeneratedLines = len(lines)
# Get all the stanza percentages, but ignore the last one, since
# we can infer it from the remaining percentage.
stanzaPercs = originalCanto.stanzaPercentages[:-1]
# Iterate through every stanza, except the last.
for stanzaPerc in stanzaPercs:
# Find out where the stanza break should go, in percentages.
stanzaBreak = round(stanzaPerc * numGeneratedLines)
# Insert a blank space at the stanza break.
lines = lines[:stanzaBreak] + [' '] + lines[stanzaBreak:]
# Now indent the newly-generated poem according to the old.
# First, get indentation statistics about the original canto.
stats = originalCanto.indentationStats
# Go through each of the indentation levels listed in its statistics.
for indentLevel in stats:
# Compute the number of lines to indent for our generated text.
numLinesToIndent = round(numGeneratedLines * stats[indentLevel][1])
# Initialize an empty list so that we can keep track of indented
# lines.
indented = []
# While there are still lines left to be indented,
while len(indented) < numLinesToIndent:
# choose a random line to indent,
lineNumber = random.randint(1,numGeneratedLines)
# so long as the line hasn't already been indented.
if lineNumber not in indented:
# Indent the line.
lines[lineNumber] = " " * indentLevel + lines[lineNumber]
# Add it to the list of indented lines.
indented.append(lineNumber)
return lines
def show(self, lines, originalCantoNumber):
"""
Displays the generated canto.
"""
print('Canto ' + str(originalCantoNumber) + '\n')
for line in lines:
# Get the line number. Add 1, since Python starts counting
# at zero.
i = lines.index(line) + 1
# Add line numbers for lines divisible by 5,
# so that the results will be easier to discuss.
if i % 5 == 0:
print(str(i) + ' ' + line)
else:
print(' ' + line)Canto I
In Canto I, Pound translates from Book XI of a renaissance Latin translation of The Odyssey. As he describes it, “I picked from the Paris quais a Latin version of the Odyssey by Andreas Divus Justinopolitanus (Parisiis, In officina Christiani Wecheli, MDXXXVIII)” (“Literary Essays,” 259). Roland John posits that he uses this particular translation, “from an obscure Latin version,” in order to “confirm that he is writing an epic. … [and as an] homage to Homer as the maker of Europe’s first epic” (11). There is more to this canto, of course—additional Homeric material, as well as Pound’s bibliographic commentary—but the Divus translation is the bulk of the canto, and so this is a good place to start.
In the CantoI class below, the variable
source_divus is populated with the first
seventy lines of Divus’s translation, originally transcribed from
Kenner’s facsimile in The Pound Era (352), but corrected with
a
copy at the Bayerische StaatsBibliothek and Pound’s own
transcription (Literary Essays 259). Pound’s transcription
expands Divus’s abbreviations and modernizes much of the spelling, but
there are still irregularities in the Latin, some of which Pound
discusses in “Early Translation of Homer” (ibid. 264). In order to mimic
the translation of Divus, the Latin text is machine-translated using an
API connected to Google Translate, with the function translateFromLatin. Since Google Translate
typically assumes that a word is a proper name if it cannot be found in
its dictionaries, and preserves the word as such, this helps to explain
the presence of the Latin words that still appear in the generated text
below. (Although this could be considered a defect of the translator
application, the presence of a few Latin words certainly comes across as
Poundian.)
The style of Canto I is alliterative, not unlike Old English verse. John explains that it is a “modified alliterative line similar to that used in [Pound’s] translation of the Early English poem ‘The Seafarer,’ chosen because it is an example of the earliest form of English verse.” William Cookson further identifies this style as “the first example of the overlaying of times and traditions in The Cantos” (4). To achieve this effect, an alliteration function was written.
The alliteration algorithm, alliterate(), possibly the first of its kind,
begins by attempting to guess the parts of speech of every word in a
line, using the NLTK. From there, it retrieves all synonyms and hyponyms
for the words using Princeton University’s WordNet, a thesaurus-like
“lexical database” of English words that organizes words into
hierarchical relations. These synonyms and hyponyms are then filtered by
part of speech, and the function chooses those with the highest numbers
of shared first letters. This constructs some veritably alliterative
verse, and some surprising lines, as well.
class CantoI(CantoWriter):
# Get a copy of the source text, a Latin translation of the Odyssey XI.
source_divus = open('divus2.md').read()
# We will need to tell other functions what canto number we're writing.
originalCantoNum = 1
def translateUsingGoslate(self, text):
"""
This is an interface to Google Translate. Of the two translation
algorithms here, this is much faster, but the API provider service
is unreliable, and so we have to have a backup.
"""
gs = goslate.Goslate()
return gs.translate(text, 'eng')
def translateFromLatin(self, text):
"""
This is a backup translation service that also uses Google Translate.
It's slower, but more reliable.
"""
txt = TextBlob(text)
return txt.translate(to="en").string
def alliterate(self, line, includeHyponyms=False):
# First, break up the line into words (tokens).
words = nltk.tokenize.word_tokenize(line)
# Next, try to find the parts of speech for the words.
pos = nltk.pos_tag(words)
# Look up all synonyms and hyponyms for the words in WordNet.
syns = [self._getSynonyms(tagword, includeHyponyms) for tagword in pos]
# Make a table of all the first letters of these words.
firstLettersSet = list(set([word[0].lower() for word in sum(syns, [])]))
synsFirsts = [[word[0] for word in thing] for thing in syns]
# Initialize an associative array of letters for storing
# letter frequencies.
letterDict = {}
# Iterate through all the letters and check to see if they're
# in a block. Make an associative array out of the results.
for letter in firstLettersSet:
# Start with the count at zero.
letterDict[letter] = 0
# Iterate through each block.
for block in synsFirsts:
if letter in block:
# Increment the letter count.
letterDict[letter] += 1
# Find the letter that occurs in the most synonyms.
maxLetter = max(letterDict, key=letterDict.get)
# Initialize a new list for the newly-alliterated words.
alliterated = []
for word, synList in zip(words, syns):
if synList == [] or len(synList) == 1:
# Keep all words that were not in the thesaurus,
# or had only one synonym.
alliterated.append(word)
else:
foundone = False # We haven't found anything yet.
for syn in synList: # Search through all synonyms.
if syn[0] == maxLetter: # If it starts with our letter,
alliterated.append(syn) # go with this one.
foundone = True # Found one!
break # We can stop looking now.
if not foundone:
# Go with the original word if we didn't find anything
alliterated.append(word)
# Stitch the sentence back together.
return self._untokenize(alliterated)
def write(self, originalCantoNumber=1):
"""Generate Canto I."""
# Translate the source from Latin.
translated = self.translateFromLatin(self.source_divus)
# Split the result into lines.
translatedLines = translated.split('\n')
# Alliterate the lines.
alliterated = [self.alliterate(line) for line in translatedLines]
# Format the lines like Canto I, according to statistics
# gathered from CantoReader().
broken = self.formatLines(alliterated, originalCantoNumber)
# Display the result.
return self.show(broken, 1)# Instantiate a new copy of the CantoI object defined
# in the class above.
c1 = CantoI()
# Execute the `write()` function defined above.
c1.write()Canto 1
Yet, when I came down to the ship, and the sea,
The vessel was first found in the sea gods,
And that which was wickedness in the ship, we set and the veils of the black:
But we did not go inside, taking cues within ourselves
5 As presently as pain, tears pouring Hubert:
We, however, from the back of the black ship, the prow
successful reached the bottom of the screen spreading good friend
Benecomata voiced serious goddess Circe.
We, however, each of the arms of the transport out in the ship,
10 simply we sat and old pilot diregebat:
They are spread throughout the whole of this twenty-four hours sails the sea trasientis:
And he killed time a sun was shadowed all the time on earth,
But this consists in the territories of the great depths of the ocean:
There are Cimmeriorum people of the province,
15 Mist and fog covered, nor has it ever had
Looks bright sun beam,
Nor when it tends to the starry heaven,
For neither from the heaven of the earth, when it is turned back on:
But the dark is dangerous stretches direct men:
20 We then deduced the ship is outside of sheep
We took ourselves again to the issue of ocean
, We passed on, so that we came to the place, which he spake, Circe:
This is a sacred Perimedes Eurylochusque
Did atomic number 53 have a sharp blade pulling a thigh,
25 The measure of how much elbow pit dug on either side:
But all around her humble offerings to the dead;
Multse first, but later with sweet wine:
Thirdly, again with water, and flour, and white robes, atomic number 53 have mixed for:
I prayed a passel, but weak heads of the dead:
30 He set out for Ithaca, but the barren woman to bread and butter his ox, which is the best course,
Sacrificing in their place, filled with good old planks:
simply privately vowed to sacrifice a sheep Tiresias
All the black sheep, which are superior to the States:
After the prayers for the dead nations has precautionibusque
35 I prayed, received a passel of sheep:
And the blood ran out of the cavity black in color, they are congregataeque
Cadavres dead souls from snake pit,
Nymphs iuvensesque endure many things of the elders,
And tender virgins, who had lately woeful way he disposed and,
40 many of the maimed air lances
The work force were killed in the war, the bloody weaponry, they,
Many people who came from elsewhere around the pit else
With a great shout, but I must pale fear took in fight.
Now, after spur his comrades say
45 Cattle, which have already been brutally bump off, still in the air,
Flay their paraphernalia, offering prayers to the gods,
Gallant to Pluto, and praised Proserpine.
simply I'm drawing a sharp sword from his thigh,
See, I did not dead inability heads
50 Blood was most move before I could hear Tiresias:
simply first semen the Elpenoris spouse:
You have not yet buried under the world there was a wide,
We have left the organic structure, in the house of Circe,
55 Infletum and a plea for another urgent task:
This indeed as iodine am the illusionist, lachrymator And, pitying in my mind,
And the swift addressed shouting words:
Elpenor, how have you come under the cloud, cloud;
Feet than I anticipated being in the black boat?
60 So atomic number 53 said,'But this adult male, to me, and mourned for his answer Him a word:
Laeritiade noble, wise Ulysses,
Fate of hurt me bad, and a mass of wine:
When you lie down, however, in the house of Circe, I will not be perceived by
atomic number 53 once turned down a ladder going through a long,
65 But I fell against the wall, but to me the neck
Of the strings is broken, the soul of them that travel down to the pits:
But now, I pray, not in the presence of those who were to come in the time to come;
Through his wife, and the father, who was brought up a small existing,
Telemachumque the only talker in the houses you left tail.
70 I know that this house is going to the pits
Aeaeam imellens benefabricatam island in the boat:
A brief comparison of this generated Canto with Pound’s original
might be useful here. Pound’s canto begins with the line “and then went
down to the ship” (A Draft of XXX Cantos, 3); the generated
canto begins “yet, when I came down to the ship, and the sea”—Pound’s
version exhibits much more economy of language, with 30% fewer words in
the line. The character represented by “I” in the generated version is
removed in Pound’s, which might serve to blur who is meant by the “I”—is
it Odysseus? Pound? (This economy of speech is something we will try to
correct in the generation of Canto II, using the meonymize function.) While line 3 in Pound is
alliterated with “s” words—“we set up mast and sail on that swart ship,”
the generator apparently alliterates on “w” words: “and that which was
wickedness in the ship, we set.” In line 5 in this generated version, we
see, mysteriously, “tears pouring Hubert” in place of Pound’s “heavy
with weeping.” (Who is this Hubert? One can only suspect that this is
either a translation error or an unusually distant hyponym that the
alliterate function is inserting.) In at
least one case, the alliterate function is
alliterating even more than Pound does—Pound’s “with glitter of
sun-rays” is rendered here as “looks bright sun beam” (line 16).
In some cases, the function alliterates until the line makes no sense—line 24, for instance, reads “did atomic number 53 have a sharp blade pulling a thigh,” which corresponds to Pound’s line “drawing sword from my hip.” The alliteration algorithm, trying to alliterate with words beginning with “a,” is looking for synonyms for the word “I.” Not realizing that it is a personal pronoun, it guesses that the word is the chemical symbol for iodine, and suggests the possible synonym “atomic number 53,” which starts with the letter “a.” To fix this issue, we will try to find synonyms for Canto II with a word sense disambiguation algorithm in place.
Canto II
Canto II presents a very different challenge than Canto I. As John Childs puts it, “Since Canto 1 is largely given over to discourse in its retelling of a portion of the Odyssey, the devices of imagism are largely absent, and, in fact, The Cantos seem to alternate between the two poles of Imagist”lyricism" and discursive “historicism”; Cantos 1 and 2 are representative of such alternation" (44). One of the characteristic features of this second imagist mode of Canto II, Childs argues, is metonymy. In fact, he continues, it is the use of metonymy that distinguishes imagism from symbolism. The algorithm that will be used to generate Canto II, then, will apply metonymic principles to a mix of Pound’s source materials.
Broadly, metonymy is, in M.H. Abrams’s definition, a process by which “the literal term for one thing is applied to another with which it has become closely associated because of a current relation in common experience” (120). A common example is “the crown” as a term meaning a king. One type of metonymy is a synechdoche, where “a part of something is used to signify the whole, or (more rarely) the whole is used to signify a part” (ibid.). Using the Princeton WordNet, we might be able to emulate metonymy to a small degree by navigating its hierarchy of word relations. The NLTK WordNet API provides functions for finding meronyms for words, for instance. A meronym is a word that is a component of another word, and WordNet charts both “part” and “substance” meronyms. Here are some example meronyms for the word “tree”:
wn.synset('tree.n.01').part_meronyms()[Synset('burl.n.02'),
Synset('crown.n.07'),
Synset('limb.n.02'),
Synset('stump.n.01'),
Synset('trunk.n.01')]
wn.synset('tree.n.01').substance_meronyms()[Synset('heartwood.n.01'), Synset('sapwood.n.01')]
The metonymy function below starts by
determining the part of speech of a word, attempts to disambiguate its
sense using the Lesk algorithm for word sense disambiguation (WSD), and
with the resulting word sense or “synset,” searches for meronyms. If
none are found, it will try searching for other ways to convert the line
into a more metonymic line.
Another way that metonymy functions is, as David Lodge explains, as a “condensation of contexture,” effected by a “transformation of a notional sentence … by means of deletion of portions of the syntagm” (quoted in Childs 36). A simple instance of this deletion is the removal of the word “like” that can transform a simile into a (metonymic) metaphor. Pound’s affinities for the economy of words of ancient Chinese poetry, coupled with his terse haiku-like experiments, makes deletion an obvious choice for Poundian generative poetics. In fact, in an early essay on the Chinese poem “The Jewel-Stairs Grievance,” he explains that despite the fact that he has “never found any occidental who could ‘make much’ of that poem,” still “everything is there, not merely by ‘suggestion’ but by a sort of mathematical process of reduction” (Early Writings, “Chinese Poetry”). What we shall be attempting here is literally a mathematical process of reduction.
Rather than delete words at random, however, we will design an
informed algorithm for metonymic deletion. Citing William E. Baker,
Childs argues that one of the syntactic modes of this metonymic deletion
is “nominalization,” that deletion “gives primary emphasis to the noun,
and that the great majority of fragments are classified as such because
they contain a noun or noun phrase which lacks a finite verb to provide
grammatical ‘sense’ to the structure” (quoted in Childs, 58-9). With
this in mind, the function metonymize will
call the function deleteVerbs in order to
delete a small proportion of verbs in each line.
The algorithm below will start with eight of Pound’s sources, taken
from Carroll Terrell’s Companion to the Cantos. These include
selections from Ovid’s Metamorphoses books III and X,
Euripedes’s Bacchae, Homer’s hymn to Dionysos, and selections
from the Odyssey and Iliad. The Ovid translations are
those of Brookes More, and the Homer translations are those of Samuel
Butler; both were downloaded from Perseus. The
text of Robert Browning’s Sordello was downloaded from
Wikisource, and the Mabinogion was downloaded from Project Gutenberg.
These sources are “mixed” together with the function sourceMix, which interpolates the source texts
every X number of lines. That mix is then “metonymized” with the metonymize function previously described. From
there, line breaks are added, and the text is formatted with stanza
breaks and indentation to resemble the original Canto II.
class CantoII(CantoWriter):
# Gather text files of some of Pound's sources for Canto II.
# Robert Browning's epic poem _Sordello_
sourceFiles = ['sordello.txt',
# Ovid's Metamorphoses, III and X
'ovid3.txt',
'ovid10.txt',
# The Odyssey XI (an English translation this time)
'odyssey-xi.txt',
# The Mabinogion
'mabinogion.txt',
# The Illiad III
'iliad-iii.txt',
# Homer's Hymn to Bacchus
'homeric-hymn7.txt',
# Euripedes's _Bacchae_
'euripedes.txt']
""" An associative array with the file names and file contents. """
sourceTexts = {filename: open('II/'+filename).read().split('\n') for filename in sourceFiles}
def reloadSourceTexts(self):
""" Reload the source files when necessary. """
self.sourceTexts = {filename: open('II/'+filename).read().split('\n') for filename in self.sourceFiles}
@property
def sourceMix(self, chunkSize=2):
# Get a fresh copy of the source texts, in case anything has changed.
self.reloadSourceTexts()
# Initialize a new list to hold the mixed lines.
sourceMixLines = []
# Set a flag so that we know when to stop.
go = True
# Keep going so long as this flag is True.
while go:
# Iterate through all the source texts,
for source in self.sourceTexts.values():
# so long as there's something left to iterate through.
if len(source) > 0:
# Get the first X lines
for line in source[0:chunkSize]:
# (as long as the line isn't empty),
if line != '':
# and add it to our new list.
sourceMixLines.append(line)
# Now delete those lines from the source.
del source[0:chunkSize]
else:
# If the source empty, we can stop now.
go = False # Stop
return sourceMixLines
def _translatePOS2(self, pos):
"""
The Lesk algorithm used in word sense disambiguation uses the abbreviations
'a', 'n', and 'v' for adjectives, nouns, and verbs, respectively, but
the POS tagger uses different abbreviations. This function translates one
to the other.
"""
if pos[0] == 'J':
return 'a'
if pos[0] == 'V':
return 'v'
if pos[0] == 'N':
return 'n'
else:
return None
def _getLineSynsets(self, tokens):
"""
Tries to detect the senses of the words by their context.
It uses the Lesk algorithm to try to guess at the sense of the word
being used, by the word's lexical similarity (thesaurus distance) to
other words in the line.
"""
# Try to detect the parts of speech first.
pos = nltk.pos_tag(tokens)
# Don't try to look up frequently used words like "a," "an," and "the."
stop = stopwords.words('english')
# Next, let's do some word sense disambiguation on the line to make sure that we're dealing smartly with each line.
synsets = [nltk.wsd.lesk(tokens, word[0], self._translatePOS2(word[1])) if word[0] not in stop else None for word in pos]
return synsets
def _getFirstMeronym(self, synset):
"""
This is a helper function to get the first part- or
substance-meronym for a given sense.
"""
pm = synset.part_meronyms()
sm = synset.substance_meronyms()
if len(pm) > 0:
return pm[0].lemma_names()[0]
elif len(sm) > 0:
return sm[0].lemma_names()[0]
else:
return None
def _getFirstHyponym(self, synset):
""" Gets the first hyponym for a synset. """
hn = synset.hyponyms()
if len(hn) > 0:
return hn[0].lemma_names()[0]
def _deleteVerbs(self, words, synsets):
""" Deletes verbs in a line, about half the time."""
for word, synset in zip(words, synsets):
# Provided the synset exists,
newSynsets = []
newWords = []
if synset is not None:
# and if the part of speech is a verb,
if synset.pos() == 'v':
# (only do this about half the time),
if random.random() > 0.5:
# remove it from the list of synsets,
for item in synsets:
if item is not None and item is not synset:
newSynsets.append(item)
for item in words:
if item is not None and item is not word:
newWords.append(item)
words, synsets = newWords, newSynsets
# and remove it from the word list.
return words, synsets
def metonymize(self, line):
"""
This looks through every word in a line, and tries to find a
meronym for it. If it can't find a meronym, it substitutes a hyponym.
"""
words = nltk.tokenize.word_tokenize(line)
synsets = self._getLineSynsets(words)
if synsets is not None and words is not None:
words, synsets = self._deleteVerbs(words, synsets)
# Let's first look for part meronyms.
newLine = []
for word, synset in zip(words, synsets):
if synset is not None:
firstMeronym = self._getFirstMeronym(synset)
firstHyponym = self._getFirstHyponym(synset)
if firstMeronym is not None:
newLine.append(firstMeronym)
elif firstHyponym is not None:
newLine.append(firstHyponym)
else:
newLine.append(word)
else:
newLine.append(word)
return self._untokenize(newLine)
def write(self):
originalCanto = CantoReader(2)
numLines = originalCanto.numLines
# Get the mixed sources from `sourceMix` above.
mix = self.sourceMix[:numLines]
metonymized = " ".join([self.metonymize(line) for line in mix])
wrapped = textwrap.wrap(metonymized, 50)
formatted = self.formatLines(wrapped, 2)
self.show(formatted, 2)c2 = CantoII()
c2.write()Canto 2
When amaze; Who will rehear anticlimax anticlimax?
Who me `` Then I Minos son scepter in his hand
canter in affirmation on the King Arthur was at
Caerlleon upon Usk; and one day atrium Narcissus'
5
fate, when known throughout the farmstead city
center cities have it coming When the its own
aristocrat, the Trojans brevet as a flight I will
of Dionysus Semele mull monad, the badlands
10 Thebans—Dionysus, whom once Semele, Kadmos'
aftereffect bring by an ancient crime.—But I am
weary with unaccustomed corvee; and see! a poplar
good luck aim the dead poltergeist and round him
5
15 son of Urien, and Kynon the son of Clydno, and Kai
the son of Kyner; and Gwenhwyvar and her blind
Tiresias, —mighty anticipator. Yet Pentheus, bold
despiser of the Gods, son of Echion, scoffed at of
dark meat whooping crane or raindrop and midwinter
20 strive them over the airflow branch water the
beach of the fruitless bay, come across like a
stripling in the first flush of manhood: his rich,
mother's daughter, bore, consign by a lightning-
25 bearing blaze. And having taken a mortal dispersed
phase instead of a convenient lawn a good pass
uranium 235 blow hill-top once, despite the bustle
And slack of audience, Pentapolin Named liquid
oxygen' the Naked cuff, monad Hades, to understudy
30 his clause[ dikai] upon them. handmaidens at
crochet by the window. And if it should be said
that there was a porter at all his compliment,
and, ball of man catcall the great anticipator,
35 upbraided him his hapless paper loss of of Okeanos
to bring death and annihilation on the Pygmies,
airspace dark bristle was luff about him, and on
his strong hard shoulder academic gown a god's,
iodine-125 am here at the Fountain of Youth of
40 Dirke and water iodine-125 gravestone here fall
back the turf and, pillowing her ego against his
single out Sordello, catch on murkily about With
ravage of six long sad hundred month. Only ``
After him I Jacob's rod the ghosts of Arthur’s
45 alcazar, there was none. Glewlwyd Gavaelvawr
eyeful. but the Achaeans countermarch silently, in
high heart, and to there swiftly head sea bay
5
thunder-stricken mother here near the palace, and
50 fag end remnants breast and mingling kisses with
her words, she told fairytale me Never, —I should
warn you first, — Of my own default option that he
had electrocute upon the mountain peak, and he had
a great bronze clubroom in his hand, unbreakable
55 for guests and strangers, and to receive them with
honour bearing And column white eighties Tiresias
of As when bell eyelet wind miserable doom signs
to one bounce and blaze of Zeus cascade
everlasting indignity of Hera against Perhaps you
60 may have heard of a swift damsel, who had this, if
not the worst Yet not the best crutch subpoena
picometer anticlimax iodine-125 story ever and
ever. habit Court of Saint James's channel to the
Hall or to the presence-chamber, and those to
65 thee, if, light denied, thine eyes, most upon the
mountain peak blouse, bad for shepherdess but
better than bandit for and big board their bay
exultingly; for they thought him the Kadmos behalf
oracle mother's daughter his gravitate much faster
70 than in the forth so By commemorate view, The very
man as he was wont to do, And `` And I card Tityus
son of Gaia stretched upon the flat and discourse
some nine acres of archipelago. couple who average
to take up their lodging. ritual dancing! The
75 morning will come, and soon the illuminance will
dawn, when cabochon further the chalk dust from
under their amphibrach as they made all son of
article him with around with the cluster-bearing
leaf shape of the allamanda. have said whether
80 her swift acceleration or her beauty you though
iodine-125 might be Aegypiidae on either beaks
calves' liver In the bare bones of the atrium King
Arthur canter upon a capital of green rushes, over
which was circulation a advent known— all hail the
85 new god Bacchus! Either millenary must build a
column to this Anglo-Saxon deity, or shalt speed
over the flat. him, and the osier alight far away
from his hands amphibrach simper evening
iodine-125 have the Phrygians, the sun-parched
90 flat of the Persians, was more worthy of your
hallelujah. When this damsel once doom past
continental divide its hateful surge, car rental
of all men monad one man them he had fly in the
face of Zeus’ mistress Leto as she was covering of
95 flame-coloured satin, and a air cushion of red
satin was under his elbow. be torn asunder; thy
be, throughout the greenwood birdlime, will infect
the finger hole with When they were close up with
one another, Alexander forward anglophile champion
100 aperture. coxswain catch out at once to his
fellows and call: arch wintry land of the Medes,
and blessed Arabian Desert, and bridal, never will
have beggary of benedick, who will only be second
moment preterit iodine-125, first to last His
105 headway as you preview it, not a live out through
Panopeus on her way to Pytho. Then Arthur babble,
“If I thought you would not sanguinary streams;
and thy life-blood bespatter blotch blots side.
hard shoulder waterskin panther, blade golden calf
110 all of Asia which charge along the skid of the
salt head sea with its beautifully-towered cities
full of your birth trauma. For your best good you
should avoid the tie birth trauma whit More in the
secret than yourselves who canter incline to `` I
115 also the stood in disparage me wait course my
sisters fall iodine-125 have millenary fusarium
wilt two harpoon with bronze bravest of the
Achaeans to meet up with him in single bind,
strong that he is? Not even the well-built
Unlike the generated Canto I, the Canto II generated above bears
almost no resemblance to Pound’s original canto, despite the use of many
of Pound’s sources. It is not without its moments of surprisingly vivid
imagery, however: “dark meat whooping crane or raindrop and midwinter /
strive them over the airflow branch water” (l. 19-20). “Branch water”
is, somewhat mysteriously, a meronym of “water,” but is surprisingly
Poundean in resonance if we recall his “wet black bough” from “In a
Station of the Metro.” As in Canto I, the appearance of isotopes
(“uranium 235” in line 27, and “iodine 125” in line 39) signals a word
sense disambiguation error, despite the use of the Lesk algorithm used
in the CantoII class. (A future version of
this program might try to filter out all chemical elements from the
hyponym tree.) At the very least, it ends in medias res, like
Pound’s canto. Where his ends “and…,” this canto ends with the sentence
fragment “not even the well-built.”
Conclusions
While the translation-and-alliteration technique of Canto I was reasonably successful, the mix-and-metonymize method of Canto II exhibited mixed success. In both cases, a more sophisticated set of functions would be needed to pass a poetic Turing test. For instance, a future version of this program might not only subsitute hypo/meronyms and delete verbs while metonymizing, but might translate “NN1 of a NN2” syntactic constructions into NN2-NN1 forms that would more closely resemble the Anglo-Saxon metaphoric compound words that Pound uses. It could also further nominalize a line by converting some verbs into nouns by traversing the lexical hierarchy, looking for nouns that are the smallest distance away. Given the time constraints of this project, however, this experiment proved to be a useful exercise in translating literary analysis into an algorithm, or, put differently, using the algorithm as a mode of literary analysis.
It is sometimes sufficient to analyze a poem by saying that it employs certain literary devices, but it is quite another to explain to a computer exactly how those devices work, on the level of the word, or even the letter. The process of analyzing a poem in order to reconstruct it is, in some small ways, a much more involved task than simply analyzing the poem for the sake of analysis. If we are to contend, for instance, that Pound employs metonymy in The Cantos, then to explain it to a computer, we have to specify exactly what we mean by metonymy, and exactly how it functions, lexically and syntactically. In that sense, although this experiment does not discover anything wildly new about Pound’s work, and neither does it succeed in creating a great poem, it nonetheless paves the way for more experiments of this kind.
Works Cited
Bush, Ronald. The Genesis of Ezra Pound’s Cantos. Princeton, N.J.: Princeton University Press, 1989. Print.
Childs, John Steven. Modernist Form : Pound’s Style in the Early Cantos. London: Associated University Press, c1986. Print.
Cookson, William. A Guide to the Cantos of Ezra Pound. London: Anvil Press Poetry, 2001. Print.
John, Roland. A Beginner’s Guide to the Cantos of Ezra Pound. Salzburg, Austria: Institut für Anglistik und Amerikanistik, 1995. Print.
Kearns, George. Guide to Ezra Pound’s Selected Cantos. New Brunswick, N.J.: Rutgers University Press, c1980. Print.
Kenner, Hugh. The Pound Era. Berkeley: University of California Press, 1971. Print.
Korg, Jacob. “The Dialogic Nature of Collage in Pound’s Cantos.” Mosaic: A Journal for the Interdisciplinary Study of Literature 22.2 (1989): 95. Print.
Pound, Ezra. A Draft of XXX Cantos. New York: New Directions, 1940. Print.
——. Early Writings: Poems and Prose. Penguin, 2005. Print.
——. Literary Essays of Ezra Pound. New Directions Publishing, 1968. Print.
Terrell, Carroll Franklin. A Companion to the Cantos of Ezra Pound. Berkeley: University of California Press, c1980-. Print.